搜索引擎工作过程非常复杂,今天和大家分享一下我所了解的百度蜘蛛是怎么实现网页收录的。
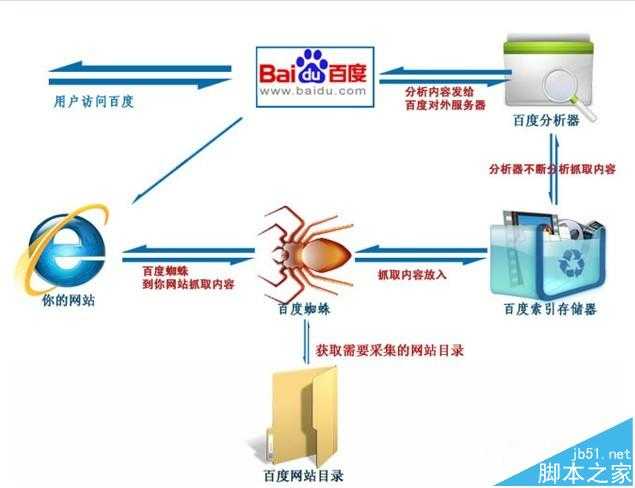
搜索引擎工作大致可以分为四个过程。
1、蜘蛛爬行抓取。
2、信息过滤。
3、建立网页关键词索引。
4、用户搜索输出结果。
蜘蛛爬行抓取
当百度蜘蛛来到一个页面时,它会跟踪页面上的链接,从这个页面爬行到下一个页面,就好像一个递归过程,这样常年累月,不止疲倦的工作。比如蜘蛛来到了我的博客首页http://blog.sina.com.cn/netSEOer,它会先读取根目录下的robots.txt文件,如果没有禁止搜索引擎抓取,那么蜘蛛就开始针对网页上的链接,进行逐一跟踪爬行。比如我的置顶文章“SEO概述|什么是SEO SEO到底是干嘛的”,引擎就会多进程式的来到这篇文章所在的网页抓取信息,如此循坏,没有终结。
信息过滤
为了避免重复爬行和抓取网址,搜索引擎会有一个记录已爬行和未被爬行的地址库,如果你有一个新网站时,你可以去百度官网提交网站的网址,引擎就会记录它,并把它归类到未爬行的网址,然后蜘蛛就会根据这个表格,从数据库中提取URL,访问并抓取页面。
蜘蛛并不会收录所有的页面,它要经过严格检测。当蜘蛛在爬行和抓取一个网页的内容时,会进行一定程度的复制内容检测,如果网页所在的网站权重低,而且大部分文章都是抄袭来的话,蜘蛛就很可能不喜欢你的网站了,不在继续爬行,也就不收录你的网站。
建立网页关键词索引
当蜘蛛抓取了一个页面之后,首先会对页面文字内容进行分析。通过分词技术,将网页的内容简化到关键词,并把关键词和对应的网址制成表格建立索引。
索引又有正向索引和反向索引,正向索引是把网页内容对应的关键词,反向是关键词对应的网页信息。
输出结果
当用户搜索了某个关键词之后,就会通过前面建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,通过引擎对网页综合评分计算以后,根据网页的评分来决定网页的先后顺序排名。
相关推荐:
网站优化 百度蜘蛛到底喜欢什么?
怎么查询ip是否为百度蜘蛛ip? tracert指令的使用方法
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
3月27日消息,苹果宣布2024年全球开发者大会(WWDC)将于6月10日至6月14日举行,巧合的是,这次大会与端午假期重合。
苹果官方表示:
在线参加 Apple 每年规模最大的开发者盛会。亲眼见证 Apple 最新平台、技术和工具的发布。了解如何创建和改进你的 App 和游戏。与 Apple 设计师和工程师互动交流,与全球开发者社区建立联系。以上活动均免费在线举行。
探索各种新的工具、框架和功能,助力你打造出理想的 App 和游戏。通过视频讲座学习新技能,与 Apple 专家进行一对一会面,以推进你的项目,完善你的构思。
Swift Student Challenge 旨在支持和鼓舞下一代开发者、创作者和企业家。太平洋时间 3 月 28 日,我们将公布今年的获奖者名单。获奖者将有资格参加在 Apple Park 举办的特别活动。我们还会选出 50 名杰出获胜者,他们将受邀前往库比提诺,获得为期三天的非凡体验,包括参加 Apple Park 的特别活动。
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。
更新日志
- 群星《歌手2024 第4期》[FLAC/分轨][563.76MB]
- RiffKitten-ChaosParade(2024)[24-44,1]FLAC
- RuneKlakegg-Nattevandrer(2024)[24-96]\FLAC
- 赖冰霞.2006-金嗓典藏辑2IN1(南方金点系列)2CD【南方】【WAV+CUE】
- 群星.1988-国语金曲尽精英VOL.2【瑞成】【WAV+CUE】
- 张宇.1999-雨一直下【EMI百代】【WAV+CUE】
- 袁娅维.2021-月亮失眠了(DELUXE)【华纳】【FLAC分轨】
- AlanBroadbent-JazzFunk(2024)[24-44,1]
- 梅艳芳《绝代芳华》开盘母带[低速原抓WAV+CUE]
- ABC唱片-《外国精逊母带直刻神奇黑胶[APE+CUE].
- 群星《天赐的声音第五季 第6期》[320K/MP3][101.43MB]
- 群星《天赐的声音第五季 第6期》[FLAC/分轨][526.16MB]
- 群星《说唱梦工厂 第2期》[320K/MP3][96.37MB]
- 杨宗宪.1994-留你留袂着【有容唱片】【WAV+CUE】
- 李翊君.2005-勇敢的爱【创意唱片】【WAV+CUE】